**### Outline 4.6 Behavioural Prediction
- Core Argument dieses Kapitels definieren
To-Do’s
- check wording
- check whether it is in scanner task fmri or outside of the scanner
- REWRITE intro sentence of 4.6 — Language + WM Place = in-scanner fMRI; NIH Toolbox Noise Comparison = outside scanner; fixed
- psostive edges in RT mean faster or slower RT? ich gehe jetzt eifnach von posituive edges faster RT aus
4.6 Behavioural Prediction
To validate the functional relevance of the resting-state networks identified in sections 4.2–4.5, we assessed whether individual differences in RSFC could predict performance on two in-scanner fMRI tasks and one out-of-scanner behavioural measure from the HCP battery.
All analyses show the ROIs of the right hemisphere, since the left hemisphere did not show significant results, following a paradigm considering the design of the tasks. The omission of significance in the left hemisphere is discussed in 5.5.
4.6.1 “What” Stream: Predicting Semantic Processing Speed
The main test of the ventral ‘what’ stream hypothesis used the Language Task Story median reaction time (Median RT). The ventral ROI model significantly predicted story Median RT (, ), with areas A5 and STGa as the strongest positive predictors, meaning that stronger resting-state coupling to areas A5 and STGa was associated with faster response times. The dorsal ROI model did not reach significance (, n.s.). This provides a clean dissociation: the semantic ‘what’ network predicts language comprehension speed, while the spatial ‘where’ network does not (Figure 4.X).
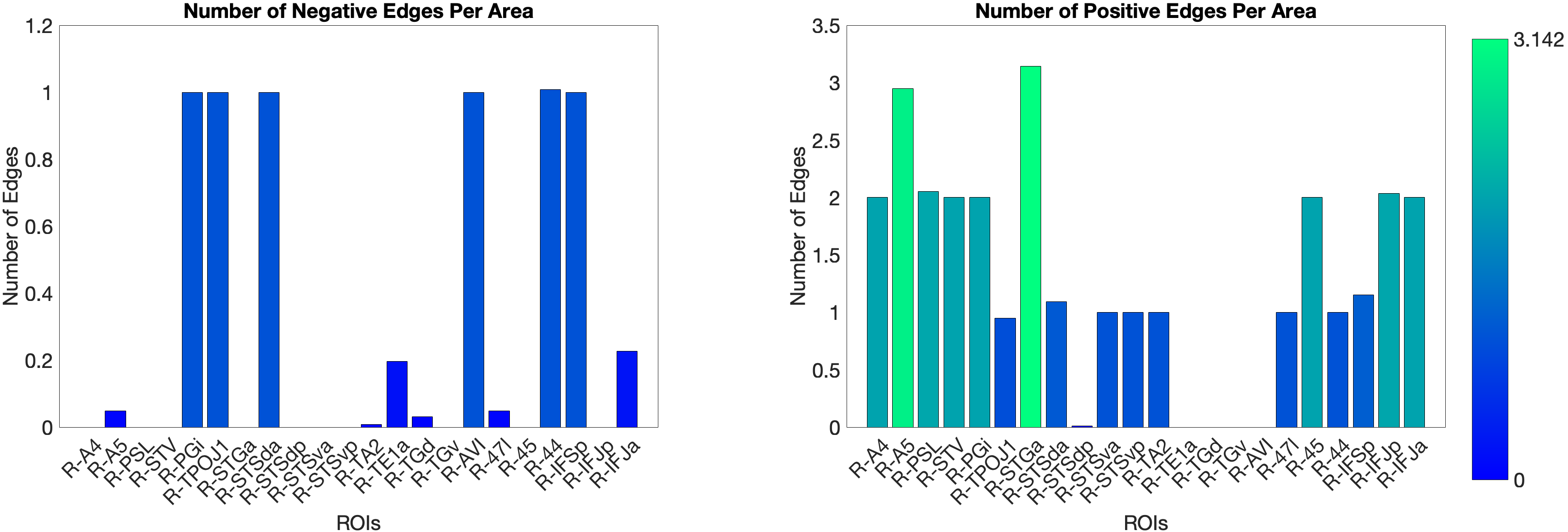
Figure 4.X: Number of predictive edges per area for the ventral ROI model predicting Language Story Median Reaction Time (right hemisphere; partial correlation, K = 371 leave-one-out cross-validation). Each bar represents the number of resting-state functional connectivity edges involving that area that contributed to the cross-validated prediction. Areas A5 and STGa emerge as the strongest positive predictors, meaning that stronger resting-state coupling of these areas to the ventral network is associated with faster semantic processing speed. The dorsal ROI model did not reach significance (R = 0.04, n.s.), confirming that this behavioural prediction is specific to the ‘what’-stream network.
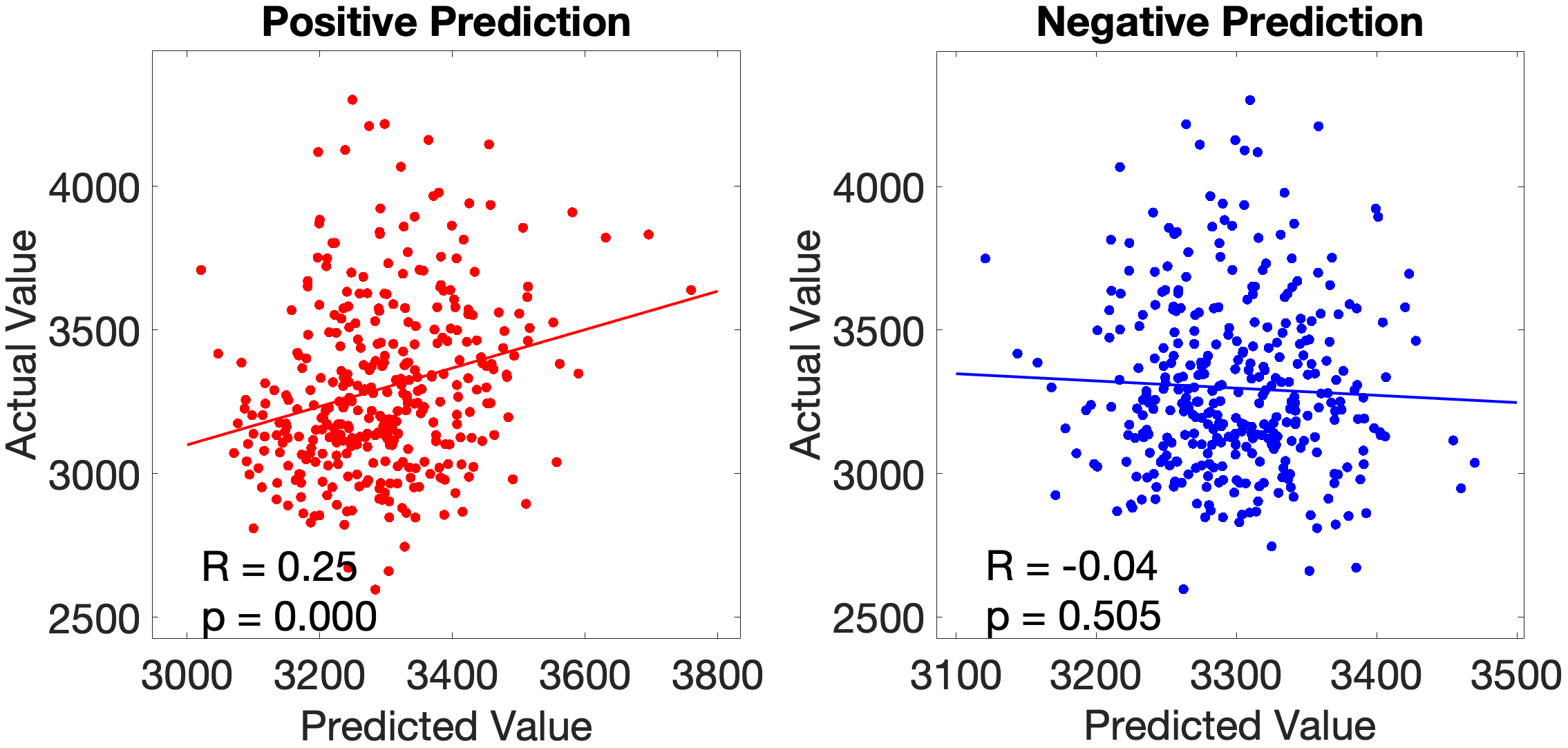
Figure 4.X: Cross-validated p-values for the Language Story Median RT prediction, ventral ROI model (right hemisphere; partial correlation, K = 371). Bars indicate significance of the cross-validated correlation per area, confirming that the ventral stream prediction is robust across leave-one-out cross-validation folds.
On the other hand, the story accuracy (Acc) shows different results. The full network predicted story Acc (, ) and both the ventral (, ) and dorsal (, ) submodels reached significance. Interestingly, area 45 presents itself as a negative predictor for accuracy, meaning stronger Area 45 coupling was associated with lower accuracy. The ‘where’-stream’s accuracy was driven by areas 43 and PF (Figure 4.Y).
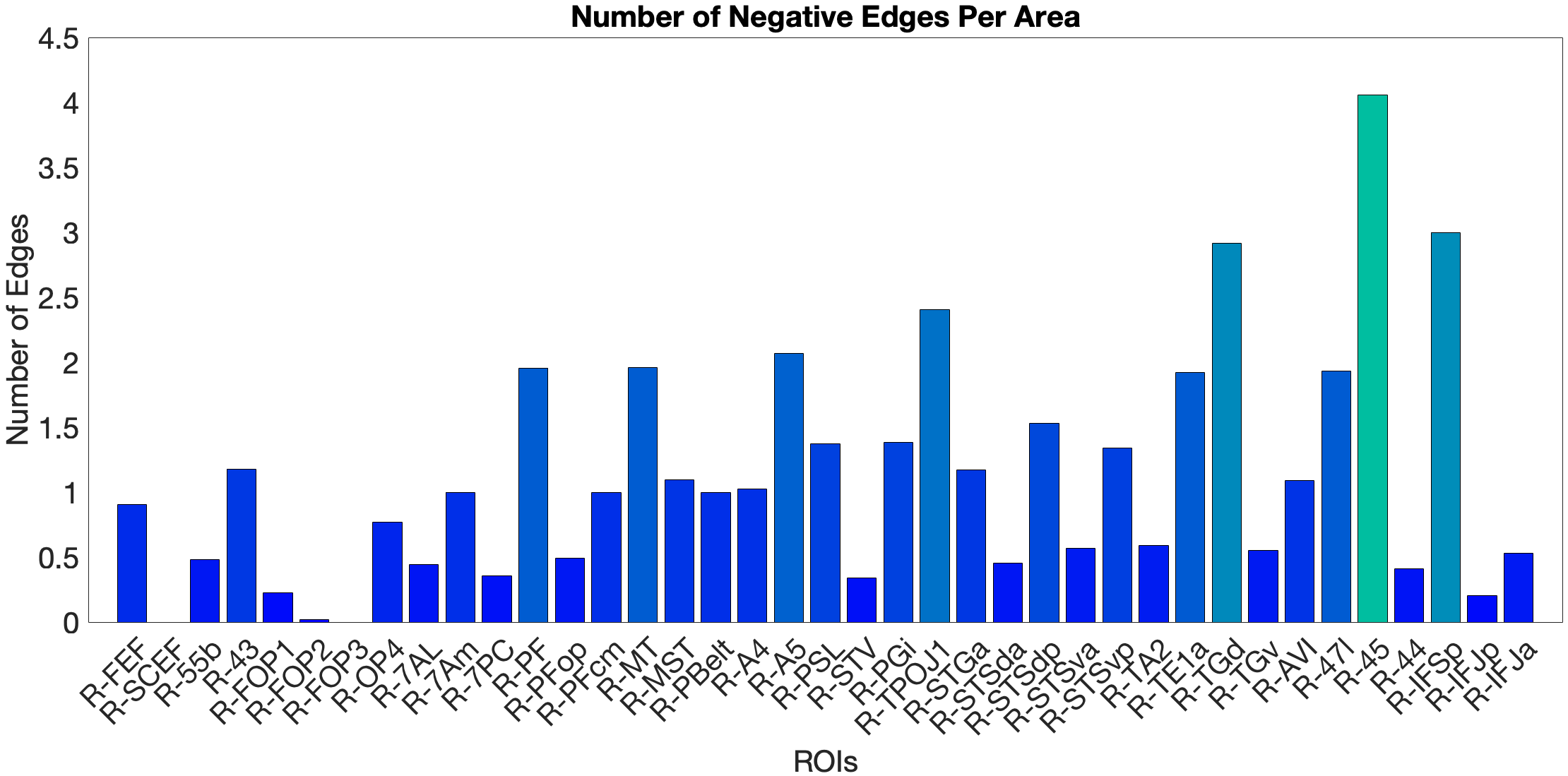
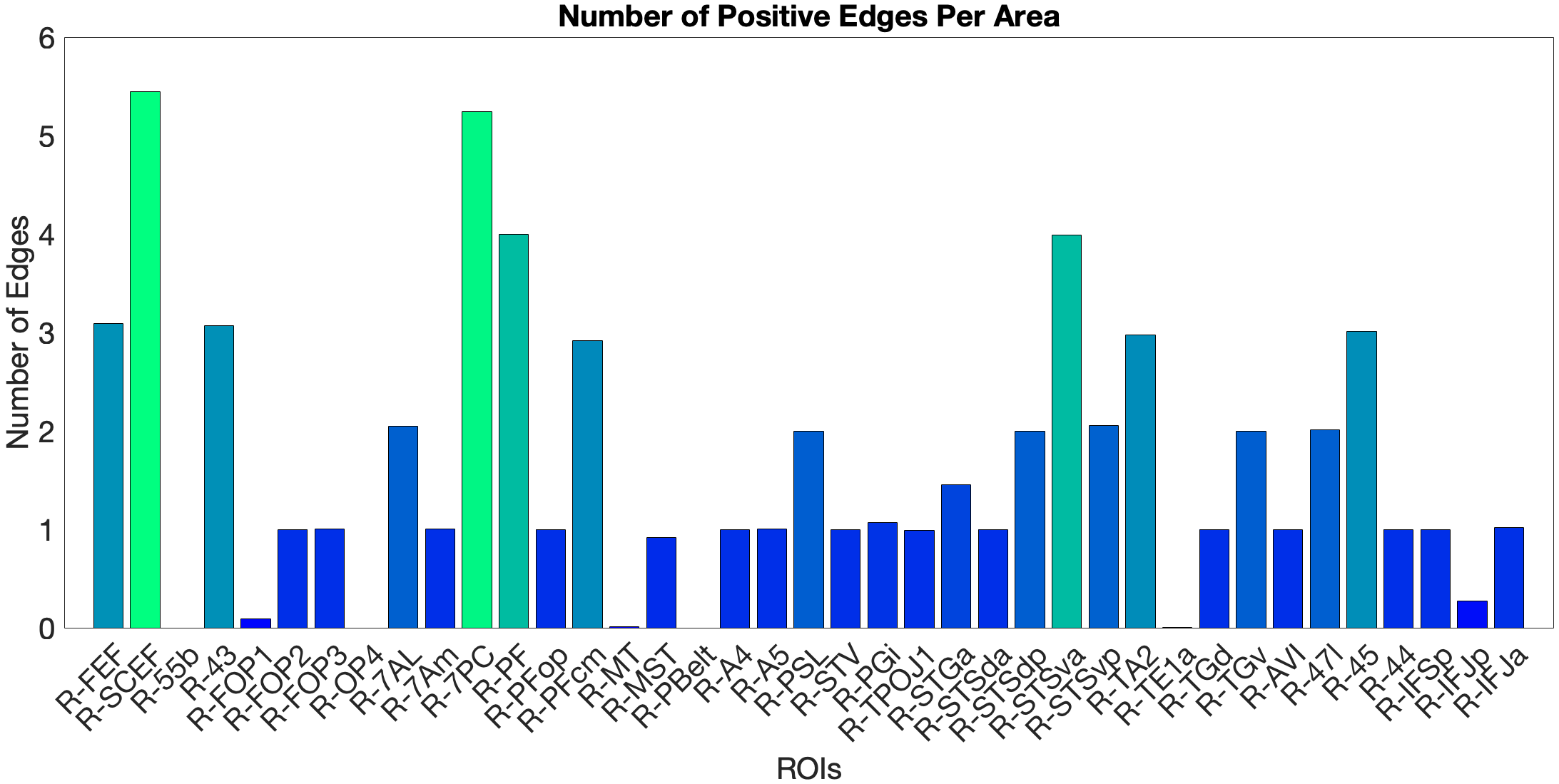
Figure 4.Y: Number of predictive edges per area for all ROI model predicting Language Story Accuracy (right hemisphere; partial correlation, K = 371 leave-one-out cross-validation). Area 45 emerges as a negative predictor, meaning stronger resting-state coupling to Area 45 is associated with lower story comprehension accuracy — consistent with an interference effect in which engagement of deep syntactic processing disrupts comprehension of semantically simple narratives. Area STSva contributes as the main positive predictor. Both the dorsal (R = 0.24, p < .001) and full-network (R = 0.38, p < .001) models also reached significance, indicating that story accuracy — unlike Median RT — reflects distributed network contributions rather than ventral-stream specificity alone.
4.6.2 Acoustic Signal Filtering (Noise Comparison)
As a control task for low-level acoustic signal filtering, we chose the NIH Toolbox Noise Comparison. The ‘what’-pathway fails to predict this task (n.s.). In the full-network model (, ) and the ‘where’-stream model (, ), we observed significant predictions. In the full-network model, area PFcm was the dominant positive predictor, with FOP3 as the main negative predictor. The ‘where’-stream submodel showed a different pattern: OP4 was the main positive predictor, while FOP3, 7AL and PBelt were the negative ones. Both models show leading predictors in opercular and parietal rather than prefrontal areas. This means RSFC in the semantic network does not generalise to acoustic noise exclusion.
4.6.3 Predicting Visuo-Spatial Working Memory
We tested the dorsal ‘where’-stream hypothesis against Working Memory Task Place accuracy (Place Acc) and reaction time (Place RT). In the full-network model (, ), SCEF and AVI were the strongest positive predictors. Notably, FEF did not emerge as a significant predictor — a null result given its hypothesised role as the primary dorsal prefrontal hub (Salmi (2009), see section 2.2.3). The dorsal submodel yielded a negative cross-validated R (, ), driven by areas 7AL and 7Am. The ventral submodel predicted Place Acc positively (, ), driven by area 47l.
For Place RT, the dorsal model produced an artefactual result () due to matrix rank collapse and is excluded from interpretation (see section 5.7). The ventral model yielded a marginally significant prediction (, ), with STSda as positive and IFJa as negative predictor. The full-network model (, ) identified MT and TA2 as negative and PSL as positive predictor.
An overview of cross-validated prediction results across all tasks and models is provided in Table 4.X. A complete listing of all target regions of interest with their final stream assignments — including areas reclassified on the basis of partial correlation results (Sections 4.4.1–4.4.3) — is provided in Appendix Table A2.
Table 4.X: Cross-validated prediction of behavioural performance from resting-state functional connectivity (right hemisphere; partial correlation, K = 371). †Dorsal WM Place RT model excluded due to matrix rank collapse.
| Task | Model | R | p | Key predictors |
|---|---|---|---|---|
| Language Story Median RT | Ventral | 0.18 | .001 | A5, STGa (+) |
| Language Story Median RT | Dorsal | 0.04 | n.s. | — |
| Language Story Median RT | Full | 0.07 | n.s. | — |
| Language Story Acc | Ventral | 0.32 | <.001 | STSva (+), 45 (−) |
| Language Story Acc | Dorsal | 0.24 | <.001 | 43, PF (+) |
| Language Story Acc | Full | 0.38 | <.001 | SCEF, 7PC (+), 45 (−) |
| Noise Comparison | Ventral | −0.07 | n.s. | — |
| Noise Comparison | Dorsal | 0.17 | .001 | OP4 (+), FOP3, 7AL, PBelt (−) |
| Noise Comparison | Full | 0.22 | <.001 | PFcm (+), FOP3 (−) |
| WM Place Acc | Ventral | 0.20 | <.001 | 47l (+) |
| WM Place Acc | Dorsal | −0.15 | .004 | 7AL, 7Am (+) |
| WM Place Acc | Full | 0.14 | .007 | SCEF, AVI (+) |
| WM Place RT | Ventral | −0.11 | .035 | STSda (+), IFJa (−) |
| WM Place RT | Dorsal† | — | — | — |
| WM Place RT | Full | −0.20 | <.001 | PSL (+), MT, TA2 (−) |